An Agentic Workflow, March 2026 Edition
March 12, 2026
I've been on this stack since October: $20/mo tier to Anthropic, $20/mo tier to OpenAI, $10/mo tier to GitHub Copilot. I don't see this changing anytime soon, either, and I use them all down to the last token if I can. Because of this, I haven't explored tools like OpenClaw extensively yet. Maybe I'm as hands on as you can get without writing any code.
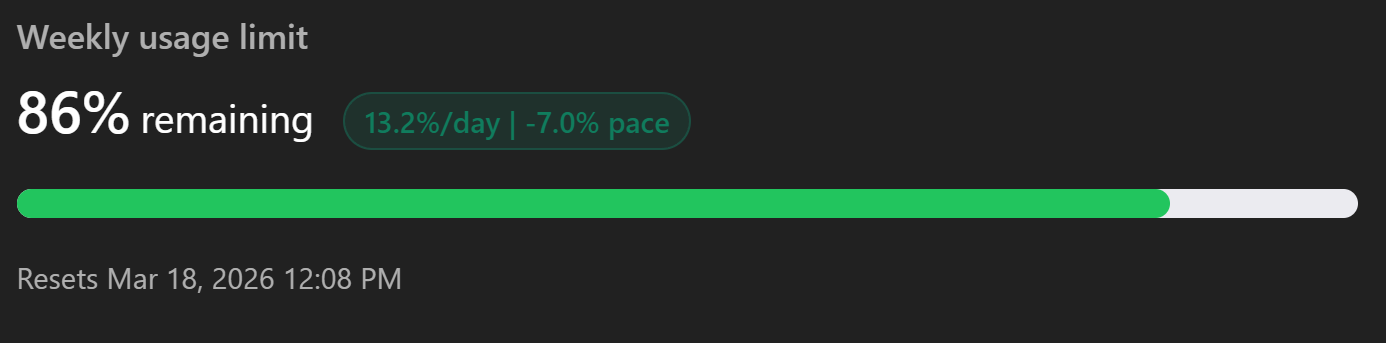
If I'm starting a normal end-to-end feature session, the first thing I check is how much usage I have left in Codex and Claude, because after using both extensively as their models got stronger and stronger, at this point - neither clearly pulls ahead.

I used to have stronger preferences here, but now it's I don't think that one is meaningfully better than the other for average feature work. Your acceptance criteria and review process matter more. The one reliable difference for me is that Claude tends to be more verbose, so if I want that I'll lean Claude otherwise I mostly pick based on remaining capacity.
I'll start by getting my environments set up to work, namely 4+ terminals spawned from
VS Code, my only editor. In the "lead dev" window I'll start either Codex or Claude
and, in a scratch or local file, start working on my prompt. I don't bother with
punctuation, clear symbol or period usage, or good spelling. At this point I know what
it can figure out from what I've told it and what I don't need to do. I just go right
down the line: ok I want users to have a new global user setting for disabling all forms of chat. in the settings view add a new row and checkbox for this. when a user checks it emit an event back to the
server/socket/settings route and add a new file there for this, then when called that event should await to grab the profile from mongo and then go find the.. and when I'm happy with it and reread it carefully, off we go.
By off we go, I don't mean paste and afk. I rarely if ever let agents write code on the first response. You can use plan mode, you can restrict permissions, but the technique I use a lot is something in a directive in their instruction markdown files:
If a prompt contains
DWCin all caps, enter "don't write code" mode for subsequent prompts (no code or file changes). This mode is scoped to the current chat session only, and stays on until a later prompt includes!DWC, which clears the mode and allows code or file changes again.
Which, interestingly, works very well for Codex and, well..

What is critical next is getting on the same page as your agent for the feature. In your first prompt, ask if they get it and whether they can repeat it back confidently enough for you to realize that what they're going to do is what you want. Also ask them for any questions here, or you'll have the problem of them just inferring things and trying to make you happy. Yes, I manually do this part of the prompt repeatedly.
Their first response back should tell you everything. In my experience one of three
things happens: they'll do exactly that and respond in a way where I'm pretty sure when
I say go, it will try to do what I want; many times though it will either come back
with questions, or say something or appear to infer something you don't want, and
you'll have to spend a bit more time and prompts making sure you are both aligned; and
rarely it just fakes it. It says something, gets something so wrong, that you
immediately realize it's not even in the right place at all and hasn't done the context
it should have. This isn't hallucinations, it's it neglecting to doing even the first step,
the research. You can usually get these back to square zero by berating it into
actually reading the files or you can /newk it from orbit.
After that I disable plan or !DWC and let it go. With gpt-5.4 and
opus-4.7 they're similar in time spent, 10 to 20 minutes for most big features,
sometimes longer, and it's not always clear why. When they're done I'll push out my
full local suite of annoyances: lint, eslint, tsc, and all unit tests.
Even now, with these models, there'll be some failures most of the time, the first time they finish a feature.
Minor lint rule failures
usually, but test failures as well. Whether or not to put it back into DWC
here is judgment, but it's probably not a bad idea. If you don't clamp down on them at
all times you might get something you don't expect, but you're usually safe here.
Once we've worked that out is the first I'll look at it locally, if necessary. I'll
just go through the feature, smoke test, and see if it's what I want and most of the
time that's it: accepted. I am of course building out a pre-MVP, so YMMV. By accepted I
mean UAT. I as a user did the UI events, they worked, thumbs up emoji (see my hair color). If not, back to the
terminal where I carefully lay out the I clicked here and this happened but it should
have had this happen style of reporting that, for now, these things can't do
themselves, and we'll walk through this path of discussion, smoke testing, and fixing
until I've decided we're at some form of feature complete. This part can take seconds, or hours.
Next is possibly the most important part, the review process. First thing is two new
agent windows and contexts, one of Codex and one of Claude, but here's where Copilot can be helpful as its usage pool can fill in gaps, especially in Claude's frequently-breached five hour
window. Now I'll have them do two code review commands. Codex's built in
/review is great, one of its best features. For Claude I use a custom
skill because without it, it tends to try to tell you how good it is when all we want
here is issues.
When those come back I'll usually take a pretty good look here, because this is where things start to matter. If your best models without context come up with problems that you weren't expecting at all, it's the biggest red flag of this process, because while the feature might be complete it's now gone beyond the feature. These can be both good and bad. Something the feature touched could have unearthed something unrelated that does need a real fix, but the worst times I've had with agentic coding full features were when it branched out cross-concern. All of this, however, is rare and most of the time code reviews will be things that it just didn't get right, didn't think through, and can be addressed by talking them through with the lead dev agent, and then the same review process again until you're satisfied. It's done.
Now is when I decide how much, if any, looking at the code actually matters here. Sometimes I'll grab venerable Sourcetree and click around looking at diffs, usually when there's a possibility of another "scan" in there, an O(n) or worse, or if I think it might change a "we don't call it global but," important type or schema. Most times I won't even bother. After doing this for months, and it only getting better, I am this confident that it's writing good code, code that looks identical to how I write it.
Why? Because I took a lot of time to make it that way: many prompts back and forth to have
these agents update their AGENTS, their instruction markdown files. If your first
impression of using agentic coding was "ick, I hate its style of code" well, fix it.
And don't fix it yourself, don't meatletter the AGENTS or CLAUDE files, tell them to do
it. In your own words update the @AGENTS.md file in the code style preferences with the change
I just made to your code in file @foo.tsx at line 253 where you changed const
to let or something and hit save, anything.
At this point you have a feature - whether you want it to pass more rigorous PR review is up to you. But as long as you know what you want, the real engineering requirements and not just product, and also of course how confident you are in your workflow and its related risk, its done. Next, I'll show the potential time savings on a project I'm finishing up, that was half written by hand by me, and half by agentic AI, and also give you some examples of the bigger types of features I'm talking about.